Cache工作原理
1. Cache基本概念
为提升CPU访问主存的性能,通常会在CPU和主存之间增加一个隐藏的小容量快速
SRAM,称为cache。将主存中经常访问或即将访问的数据的副本调度到小容量的SRAM中,使得大部分数据访问都可以在其中进行,从而提升性能。
- CPU通过字节地址访问快速的
cache,通过一定查找机制判断数据是否在cache中- 如果数据在
cache中,则称为数据命中(cache hit),命中访问时间为 $t_c$,包括查找时间和cache访问时间 - 如果数据不在
cache中,则称为数据丢失(cache miss),需要将缺失的数据从主存调入cache中;数据缺失的访问时间称为缺失补偿(miss penalty),包括数据查找时间、主存访问时间、cache访问时间,通常用主存访问时间 $t_m$ 表示。
- 如果数据在
- 为了便于比较和快速查找,
cache和主存都被分成若干个固定大小的块,每个块包含若干字,数据缺失时将数据所在块载入cache中 [这种预读策略可以充分利用空间局部性,提高顺序访问的命中概率]。 - 数据分块后,地址可以分为块地址和偏移地址,
cache容量较小,因此主存地址字段长度大于cache地址字段长度。
命中率(评价 cache 性能)
设 $N_c$ 为运行期间命中
cache次数,$N_m$ 为从主存访问次数,命中率 $h$ 为:$1-h$ 称为缺失率。
$t_c$ 表示命中访问时间,$t_m$ 表示缺失访问时间,平均访问时间 $t_a$ 为
$e=t_c/t_a$ 为访问效率,$r=t_m/t_c$ 为主存相对
caceh访问时间的倍数,显然访问效率 $e $ 与 $r$ 和 $h$ 中有关。
2. 程序局部性
时间局部性:当程序访问一个存储位置时,该位置在未来可能会被多次访问。比如程序的循环结构和调用过程。
空间局部性:一旦程序访问了某个存储单元,则其附近的存储单元也即将被访问。如指令代码、数组、结构体等顺序存放的结构。
3. Cache 读写流程
Cache 读流程较为简单,略过。
Cache 写流程:
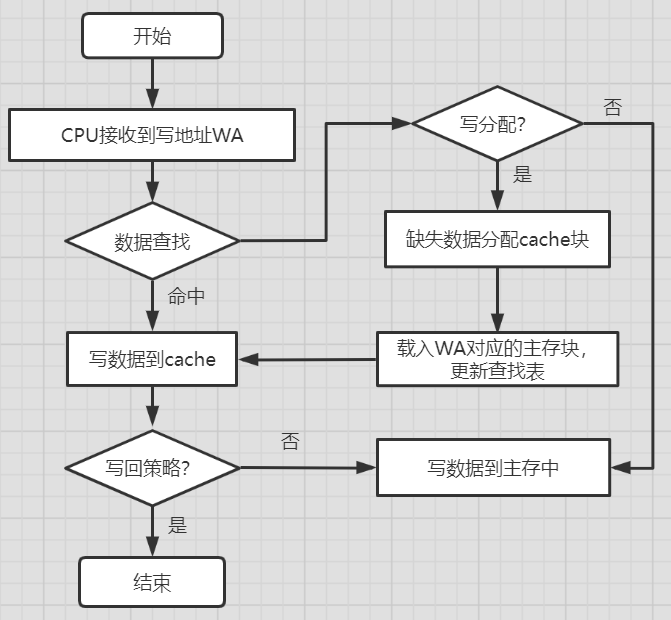
数据缺失时有两种不同策略:
- 若为写分配法,则需将
WA对应的数据块载入Cache中,再进行写命中相同流程。 - 若不为写分配法,则将数据写入主存即返回。
新写入 Cache 的数据域主存数据不一致,称为脏数据。
数据写入完成后:
- 若为写回策略,则写入操作结束,这种方式响应最快,但会产生不一致性。
- 若为写穿策略,则需将脏数据写入主存后返回,响应速度慢,但不会产生不一致性。
Cache 实现的关键技术
- 数据查找:快速判断数据是否在
Cache中 - 地址映射:主存数据块如何放置到
Cache中 - 替换策略:
Cache满后如何替换数据块 - 写入策略:如何保证
Cache与主存一致性
4. 地址映射
将主存地址空间映射到
Cache地址空间,即载入Cache块的规则。
- 全相联:主存块可以映射到
Cache任意数据块- 直接相联:主存块只能映射到
Cache中固定块- 组相联:主存块只能映射到
Cache固定组中的任意块
4.1 全相联映射
新的主存块可以载入
Cache中任何一个空位置,只有Cache满时才进行数据块置换。
Cache利用率最高,查找成本较高,CAM提供查找功能。
- 由于主存块可以放置在任意块中,为方便查找,需记录 有效位、主存块地址标记、脏数据标志位、淘汰计数等。
- 通常将一个
Cache数据块和标志信息一起称为一个Cache行/槽,有多少Cache数据块对应有多少Cache行。
主存地址划分为块地址(tag)和块内偏移地址(offset)两部分,长度分别为 $s,w$,
Cache块大小为 $2^w$ 字节,Cache缓冲区容量为 $n\times 2^w$ 字节,只考虑有效位和主存块地址,Cache实际容量为 $n\times (1+s+8\times 2^w)$,主存容量为 $2^{s+w}$ 字节。
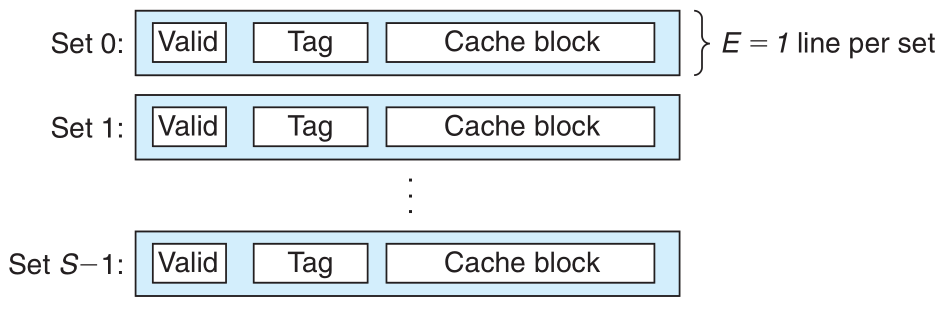
全相联映射访问过程:主存 tag 字段将与所以行中 tag 字段进行比较
valid有效位必须设置为1tag必须与主存tag匹配- 3位
offset决定选中哪一个字
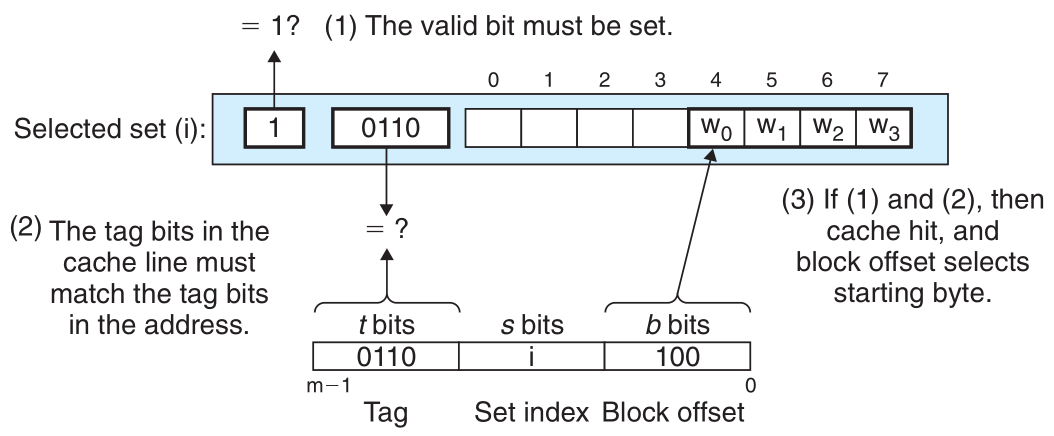
全相联映射方式特点:
- 主存块映射到
Cache任意一行,Cache利用率高Cache有空行就可以插入,Cache冲突率低- 查找需要并发查找每一行,硬件成本高,只适合小容量
CacheCache满时需进行替换,替换算法复杂
4.2 直接相联映射
每一个主存地址只能映射到
Cache固定行,映射规则为:$cache 行号\;i=主存块号\; j\mod(cache 行数 \;n)$
等效于将主存块分为与
Cache行数相同的分区,因此主存地址分为:区地址 [tag],区内行索引 [index],块内偏移地址 [offset]。
直接相联映射访问过程:
index字段选中对应的Cache行valid有效位必须设置为1tag必须与主存tag匹配- 3位
offset决定选中哪一个字
直接相联映射的特点:
- 主存块只能映射到
Cache中固定行,Cache利用率低,命中率低index相同的主存块映射Cache同一行,Cache冲突率高 [小声bb:冲突率高不就是利用率低吗,跟第一条差不多]- 查找只需与对应行的标记字段
tag进行比较,硬件成本低- 无须使用复杂替换算法
4.3 组相联映射
Cache分成固定大小的组,每组有 $k$ 行,称为 $k-$路组相联,主存数据先采用直接相联映射定位到Cache固定的组,再采用全相联映射到组内任意Cache行。组相联映射规则:$cache \; 组号=主存块号\mod (cache组数)$
Cache 模型:
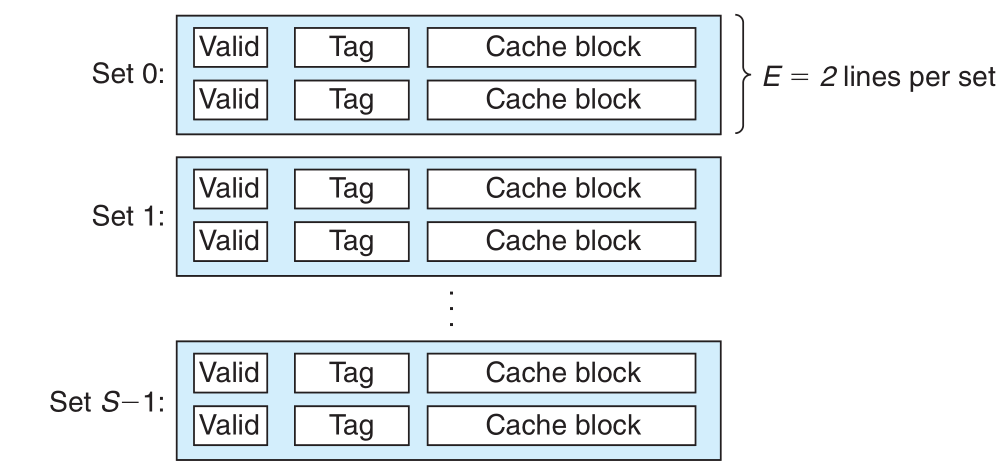
组相联Cache映射方式:
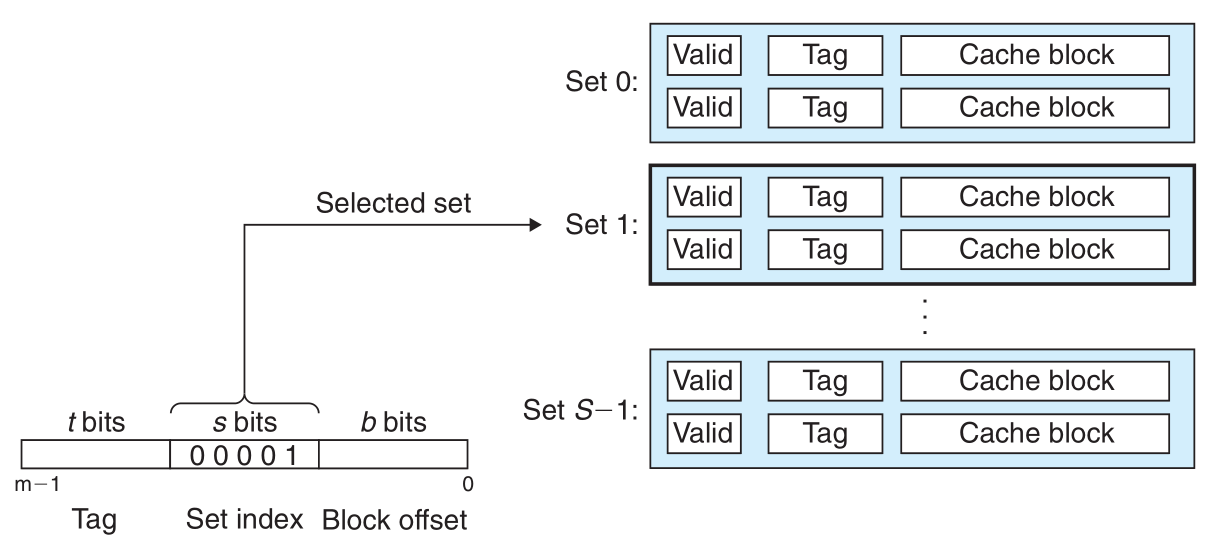
组相联映射访问过程:
index字段选中对应的Cache行- 组中的任何一行都可以包含映射到这个组的任何内存块。 因此缓存必须搜索组中的每一行,搜索其标记与地址中的标记匹配的有效行。 如果缓存找到这样的一行,那么就有一个 hit。
valid有效位必须设置为1tag必须与主存tag匹配- 3位
offset决定选中哪一个字
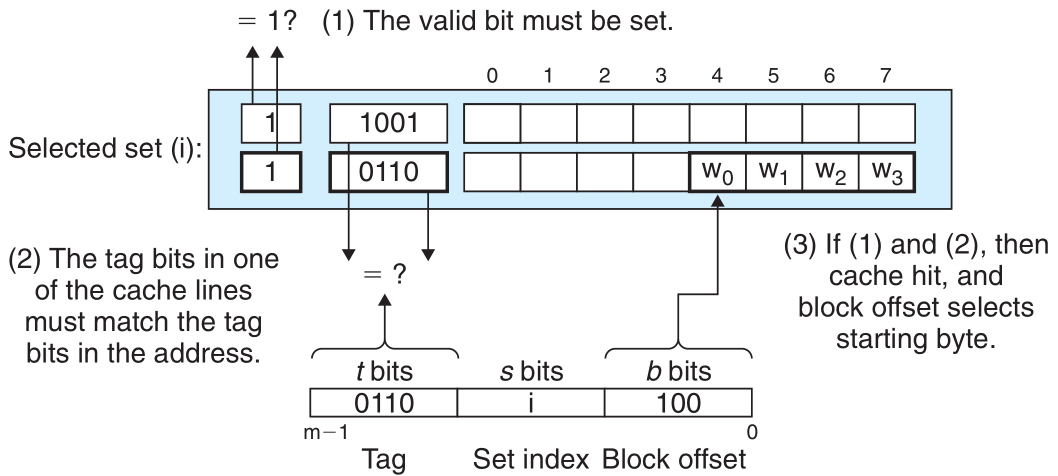
组相联映射的特点:
- 每一组多路比较器大幅减少,为各
Cache共享,硬件成本更低- 每组只有一个
Cache行时,变成直接相联映射- 整个
Cache只有一组时,变成全相联映射
5. 替换算法
替换算法与
Cache组织方式相关:直接相联映射不需要替换算法,因为一个主存块只能存放在一个特定行;
全相联映射执行替换算法时涉及所有行;
组相联映射执行替换算法设计特定组的所有行。
5.1 FIFO算法
先进先出算法按照数据块进入
Cache先后决定替换顺序,需要替换时,最先被载入的Cache行被替换。需记录每个
Cache行载入Cache的时间戳特点:
- 系统开销较小,但不考虑程序访问的局部性,有可能导致
Cache命中率低
5.2 LFU算法
最不经常使用算法将访问次数最少的
Cache行替换,每行需设置淘汰计数器,新载入Cache行为0,每命中一次计数器+1,替换时对所有可能替换行的计数值比较,计数值最小的替换。特点:
- 计数器统计
Cache启动后至今的访问次数,不能反映近期访问情况。
5.3 LRU算法
近期最少使用算法将近期最久未访问的
Cache行进行替换。也需设置计数器,Cache命中行计数器清0,其余行+1,替换时对所有可能替换行的计数值比较,计数值最大的替换。特点:
- 保护了刚载入
Cache的新数据,符合Cache工作原理,有较高命中率。- 实现难点为比较多行计数器,2-路组相联
Cache能大大简化情况。
5.4 随机替换算法
随机替换算法对特定的行中随机选取一行进行替换。
特点:
- 硬件实现最容易,速度快。
- 随意换出的数据可能即将访问,降低命中率。负面影响随着
Cache增大而减小。
6. 写入策略
写回法(Write-Back)
CPU对
Cache写命中时,只修改Cache内容,不立即写入主存,只有此行被替换时才将脏数据写回主存。
- 这种策略使
Cache在读写操作均起到高速缓存作用。 - 每个
Cache行必须有一个修改位,即脏位(dirty bit),改写过则为1,未改写则为0 - 由于不一致性,DMA操作可能获得的是旧数据
写穿法(Write-Through)
又称直写法,
Cache命中时,同时对Cache和主存中同一数据块进行修改。Cache无需脏位,替换时可直接替换。
- 在多核CPU下,每个核都有对应
Cache,因此即使写穿法也无法保证Cache同步更新。
以上就是关于 Cache 的全部内容,若还有知识点再进行补充。
参考:
计算机组成原理(微课版),大萝卜
CSAPP(3rd edition)



